Acoustic Adversarial Attacks on Computer Vision Systems
A cheap directional speaker can blur a camera sensor enough to fool AI models. Here is what operators of camera-driven systems need to know and do.
June 16, 2026·9 min read
Frequently asked questions
Do we need to worry about this if our cameras are indoors and the public cannot reach them?
Lower priority, but not zero. Indoor environments still have employees, contractors, and visitors. The threat model question is who can stand within speaker range, not whether the camera is outdoors. Most indoor sites will spend more on the blur monitor than on physical mitigations.
Will mechanical isolation actually stop this attack?
It raises the cost, it does not eliminate the attack. A heavier housing and rubber mounts mean the attacker needs a louder speaker, closer range, or a more directional setup. Combined with the blur monitor and fallback policy, the residual risk is small enough that most operators can accept it. Critical systems (autonomous vehicles, perimeter defense) should add redundant sensors as well.
How does this compare to just adversarially training the model?
The only platform to run an AI-native company.
14-day trial. No DevOps. No Sales call. Provisioned in under a minute.
Adversarial training helps with digital pixel perturbations. The acoustic attack produces real motion blur, which is closer to a normal image quality problem than a crafted adversarial example. Training the model on more blurred images helps it degrade gracefully, but it does not solve the problem; a sufficiently blurred image carries no information regardless of how the model was trained. The right response is to detect bad input and route around it, not to push the model harder.
Who owns this risk in a typical org?
Today, often nobody. Security owns the network, IT owns the cameras, the data team owns the model, and operations owns the decision. The acoustic attack crosses all four. The practical answer is to put it in the AI governance committee's threat model and assign the mitigation to whichever team owns the camera deployment. If you do not have an AI governance committee, this is one of the reasons to start one.
Is there evidence this is being used in the wild?
The research is recent and the public record of in-the-wild use is thin. That is not a reason to wait. The mitigations (mechanical isolation, blur monitoring, fallback policies) all pay for themselves against ordinary failure modes: dirty lenses, hardware faults, environmental conditions. The acoustic attack is the worst-case version of a problem you already have.
A speaker aimed at a camera can blur its image enough to fool the AI behind it. No hacking, no network access, just sound.
This matters for security cameras, drones, robots, and any business decision driven by a camera feed.
Operators should treat cameras as physical sensors with a real attack surface, not as trusted inputs.
Mitigations are mostly mechanical (vibration isolation, redundant sensors) plus eval-driven monitoring of model confidence.
Budget: a few hundred dollars of mounting and a confidence-drift dashboard prevents most of the operational risk.
A new line of research shows that a cheap speaker pointed at a camera lens can shake the sensor enough to degrade the AI model reading from it. The work, Giving AI a Headache: Acoustic Adversarial Attacks to Computer Vision Applications, is worth reading if your operation depends on camera feeds for decisions: package sorting, perimeter security, driver monitoring, retail analytics, quality inspection on a line. This post translates the finding into what an operator should do on Monday morning.
What the attack actually does
The camera in your warehouse, your delivery van, or your front gate is a physical object. Its lens sits in a housing. Sound is pressure waves. If you push enough pressure at the right frequency into that housing, the lens assembly vibrates. The image smears. The AI model that was trained on clean images now sees a smear and either misclassifies it or returns low confidence.
The researchers show this works at distances and volumes that are plausible in the real world, not just in a soundproof lab. The attacker does not need to touch the camera, see its screen, or get on its network. They need a directional speaker and line of sound to the device.
The business translation: a camera feed is a sensor reading, and like any sensor reading it can be jammed. Treat it that way in your risk model.
Diagram of a speaker directing sound at a camera housing, causing lens vibration
Why this is different from a normal adversarial attack
Most adversarial machine learning research deals with digital perturbations: pixels nudged in software to fool a classifier. Those attacks assume the attacker can edit the image bytes. That is a strong assumption in a deployed system; usually they cannot.
The acoustic attack skips that whole problem. It corrupts the image at the point of capture, before any software runs. From the model's perspective, the image is just bad. From the attacker's perspective, the only requirement is being within speaker range.
[attacker speaker] ))) sound waves ))) [camera lens housing] | v shaken sensor | v blurred image | v model returns wrong label or low confidence | v your automated decision is now wrong
Where this hits real businesses
The honest answer is: anywhere a camera feeds a model that makes or supports a decision without a human in the loop. The list is longer than most operators realize once they walk the floor.
Application
Decision driven by camera
Cost of a wrong decision
Acoustic attack realistic?
Warehouse package sorting
Route to bin
Misrouted parcel, manual rework
Yes, conveyors are noisy already; an attacker blends in
Perimeter security camera
Trigger alert or ignore
Missed intrusion, false alarm fatigue
Yes, outdoor speakers are cheap and concealable
Retail loss prevention
Flag suspected theft
Wrongful accusation, lost goods
Partially, indoor acoustics are messier
Driver monitoring in a fleet vehicle
Score driver attention
Insurance dispute, missed fatigue event
Yes, in-cabin speakers exist already
Production line quality inspection
Pass or reject part
Defective product shipped, good product scrapped
Yes, line is loud, attacker has cover
Drone delivery navigation
Obstacle detection
Crash, damaged goods, liability
Yes, drones have lightweight housings
The pattern: anywhere your camera is in a place where strangers can stand within roughly ten meters with a battery and a speaker, you have exposure. The exposure is higher when the environment is already noisy, because the attack tone hides in the noise.
What operators should do, in order
You do not need to redesign your stack. You need a short, ordered checklist.
Inventory cameras by decision impact. List every camera, then mark which ones drive automated decisions and which ones are only viewed by humans. Humans are robust to a little blur; models are not. The automated set is where you spend money.
Walk the physical site. For each high-impact camera, ask: how close can an unknown person get? Could they aim a directional speaker at the housing? If yes, that camera goes on the mitigation list.
Add mechanical isolation. Rubber grommets, foam mounts, and heavier housings absorb vibration. This is a one-time hardware spend, often under one hundred dollars per camera, and it raises the volume an attacker needs by a meaningful margin.
Log model confidence, not just model output. Most teams log the final label. Start logging the confidence score and the timestamp. A sudden drop in average confidence across one camera is your tripwire.
Set an eval that runs on the live feed. Sample frames, score them for blur, and alert when blur exceeds a baseline. This is cheap to build.
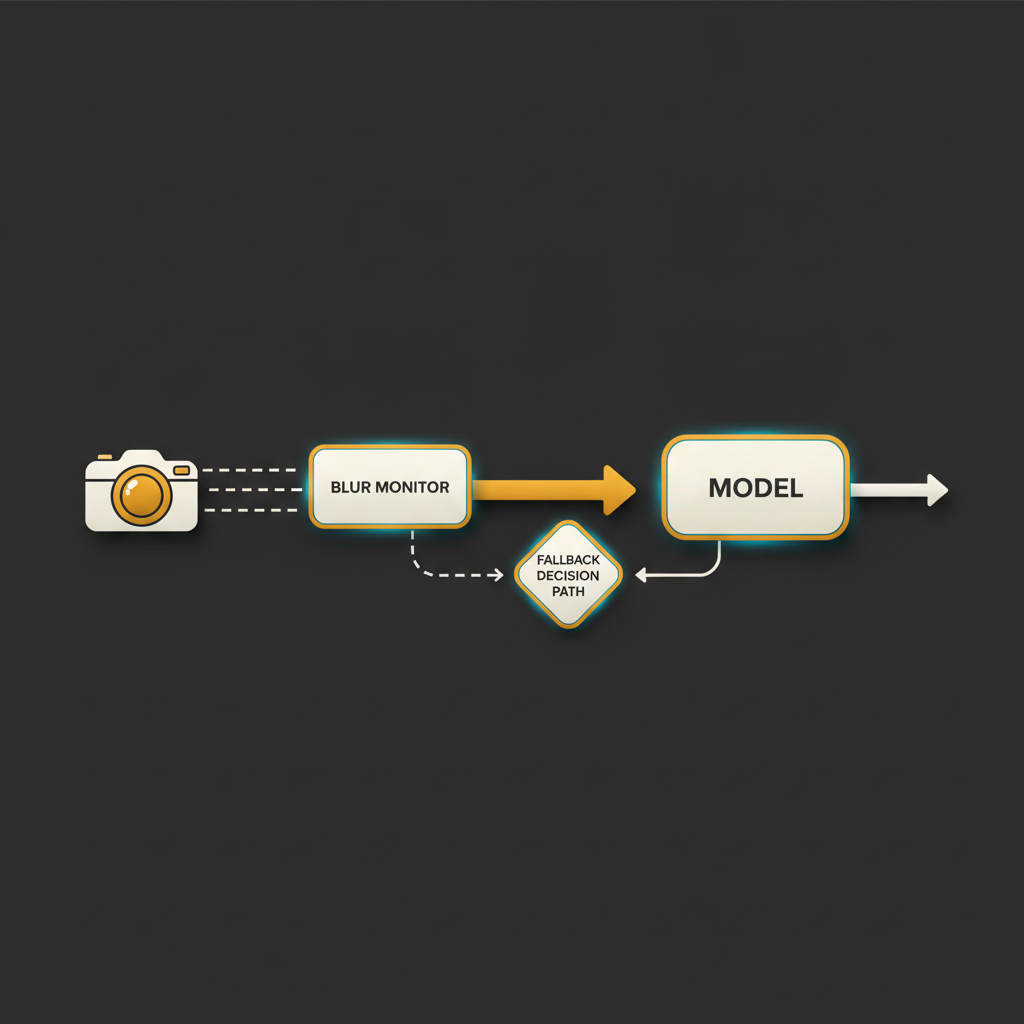
Add a fallback decision path. If confidence drops below a threshold, the system should not silently guess. It should escalate to a human, hold the package, or stop the line.
A working blur monitor you can deploy
This is the eval-driven operations piece. The goal is not to detect the attack directly; it is to detect that the model's input has degraded, for any reason, and route the decision somewhere safer.
# Samples frames from a camera, scores blur, alerts on drift.# Run this as a sidecar to whatever model is consuming the feed.import cv2import timeimport statisticsimport requestsCAMERA_URL = "rtsp://camera-7.warehouse.local/stream"ALERT_WEBHOOK = "https://ops.example.com/hooks/camera-drift"WINDOW_SECONDS = 60DROP_RATIO = 0.5 # alert if blur score drops to half the baselinedef blur_score(frame): # Higher number means sharper image. Standard Laplacian variance. gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) return cv2.Laplacian(gray, cv2.CV_64F).var()cap = cv2.VideoCapture(CAMERA_URL)recent = []baseline = None
That script does one thing: it watches a camera, scores how sharp the picture is, and pings your ops channel when the picture gets noticeably blurrier than usual. It will catch acoustic attacks. It will also catch a dirty lens, a fogged housing, a misaligned mount, and a failing sensor. All of those degrade your automated decisions in the same way.
The fallback policy in configuration
Once you have a confidence and blur signal, the model's caller needs to know what to do when the signal goes bad. Express this in a config file your operations team can read, not buried in code.
# Decision policy for the package sorting line.# Read by the routing service before each sort decision.camera: camera-7model: parcel-classifier-v4thresholds: min_confidence: 0.82 min_blur_score: 120on_violation: action: divert_to_manual_lane notify: - slack: "#warehouse-ops" - pagerduty: "warehouse-shift-lead" cool_down_seconds: 300audit: log_frame: true retain_days: 30
The point of writing the policy this way: your shift lead can read it, your auditor can read it, and your governance review can sign off on it. The mechanism (acoustic attack, dirty lens, hardware fault) does not matter to the policy. The policy is: when our input is bad, we stop guessing.
Where this fits in AI governance
If you are responsible for AI risk at an operating company, this research is a clean example of why governance needs to extend past the model into the physical world. A model card describes the model. A data sheet describes the training data. Neither tells you that the camera bolted to the loading dock can be jammed by a kid with a Bluetooth speaker.
The governance practice that catches this is sensor-level threat modeling. For each camera, microphone, or other physical input feeding a model, write down: who can reach it, what can they do to it, and what does our system do when its reading is wrong. The acoustic attack is one row in that table. Glare, fog, paint, tape, laser pointers, and infrared LEDs are other rows. The acoustic finding adds a row; it does not change the practice.
flowchart LR A[Camera sensor] --> B[Blur and confidence monitor] B --> C{Signal healthy?} C -- yes --> D[Model decision] C -- no --> E[Fallback: human review or hold] D --> F[Automated action] E --> G[Ops alert and audit log] F --> H[Audit log]
This is the same shape as any eval-driven operations diagram: the model output is gated by a live evaluation of input quality, and unhealthy inputs route to a slower but safer path. The acoustic research is a reminder that the evaluation needs to cover the sensor, not just the model output.
What this costs and what it saves
The hardware mitigations are cheap. Rubber mounts, denser housings, and acoustic foam run tens of dollars per camera. A blur and confidence monitor is a few days of engineering time and runs on a small server alongside your existing model serving.
The savings show up in two places. First, you avoid the cost of acting on bad decisions: misrouted parcels, missed intrusions, wrongful flags. Second, you avoid the cost of the incident review when something goes wrong and nobody can explain why the model failed. With the monitor in place, your post-incident report writes itself: confidence dropped at this timestamp, the system diverted to manual review, here is the audit log.
For a mid-sized operation with twenty high-impact cameras, the all-in cost is in the low five figures. The avoided cost of a single misrouted shipment, a single false-negative security event, or a single regulatory finding clears that easily.
while True:
ok, frame = cap.read()
if not ok:
time.sleep(1)
continue
score = blur_score(frame)
recent.append((time.time(), score))
recent = [(t, s) for t, s in recent if time.time() - t < WINDOW_SECONDS]