SkMTEB: The Slovak Text Embedding Benchmark Explained
SkMTEB is the first MTEB-style benchmark for Slovak, covering 31 datasets across 7 task types to help operators pick the right embedding model.
June 14, 2026·9 min read
Frequently asked questions
Do I need to read the SkMTEB paper to act on this?
No. The actionable point is that Slovak embedding quality varies a lot between models and you can measure it cheaply. The paper is useful if you want to short-list models before running your own eval. Skim the model rankings and pick two or three to test on your data.
We use an English-first product. Does any of this apply?
Yes, if you serve Slovak customers in any channel. The embedding model behind your search or chatbot is doing language-specific work whether you configured it to or not. The risk is the same in every Central European market: you inherit an English-first default and never notice the quality drop until churn shows up.
How big does my eval set need to be?
Two hundred examples is enough to make a decision between two candidate models on retrieval. For classification, you want at least 30 per class. The point is directional confidence, not statistical perfection. Start small, expand the set every time a real failure shows up in production.
The only platform to run an AI-native company.
14-day trial. No DevOps. No Sales call. Provisioned in under a minute.
Should we wait for a bigger multilingual model from a major lab?
Probably not, if Slovak quality is hurting today. The SkMTEB results suggest that adapting an existing model on Slovak data closes most of the gap. Waiting six months for a new release means six months of degraded customer experience. Run the eval, pick the best available option, plan to re-evaluate quarterly.
Who on my team should own this?
A data or ML engineer runs the eval. An operations lead owns the eval set and the decision rule. A product manager owns the downstream metric (resolution rate, deflection rate, search click-through). The benchmark is a shared artifact, not an engineering toy. Treat it like a financial control: someone signs off when the number changes.
If your business operates in Slovak, generic multilingual embeddings probably underperform: SkMTEB now lets you measure the gap.
SkMTEB covers 31 datasets across 7 task types, roughly four times the Slovak coverage of prior multilingual benchmarks.
Picking the wrong embedding model quietly raises support costs, hurts search quality, and drags down retrieval-augmented chat accuracy.
Operators should run a short, internal eval against SkMTEB-style tasks before signing a vendor contract or freezing a model choice.
Adaptation (fine-tuning an existing multilingual model on Slovak) often beats waiting for a bigger general-purpose release.
If your customer support, search, or document workflows run in Slovak, the quality of your text embeddings is a hidden line item. Bad embeddings mean worse retrieval, weaker classification, and more human review. A new benchmark called SkMTEB, the Slovak Massive Text Embedding Benchmark, gives operators in Slovak-speaking markets a concrete way to compare models on the tasks that actually drive revenue and risk (arXiv:2606.13647).
Why this matters before we talk about benchmarks
Most B2B AI buyers in Central Europe inherit an English-first stack. The vendor demo runs in English, the embedding model is multilingual "by default," and nobody checks whether it actually works in Slovak until a customer complains. By then, you have a knowledge base full of vectors that retrieve the wrong article 30 percent of the time, and your agent has been hallucinating policy answers for a quarter.
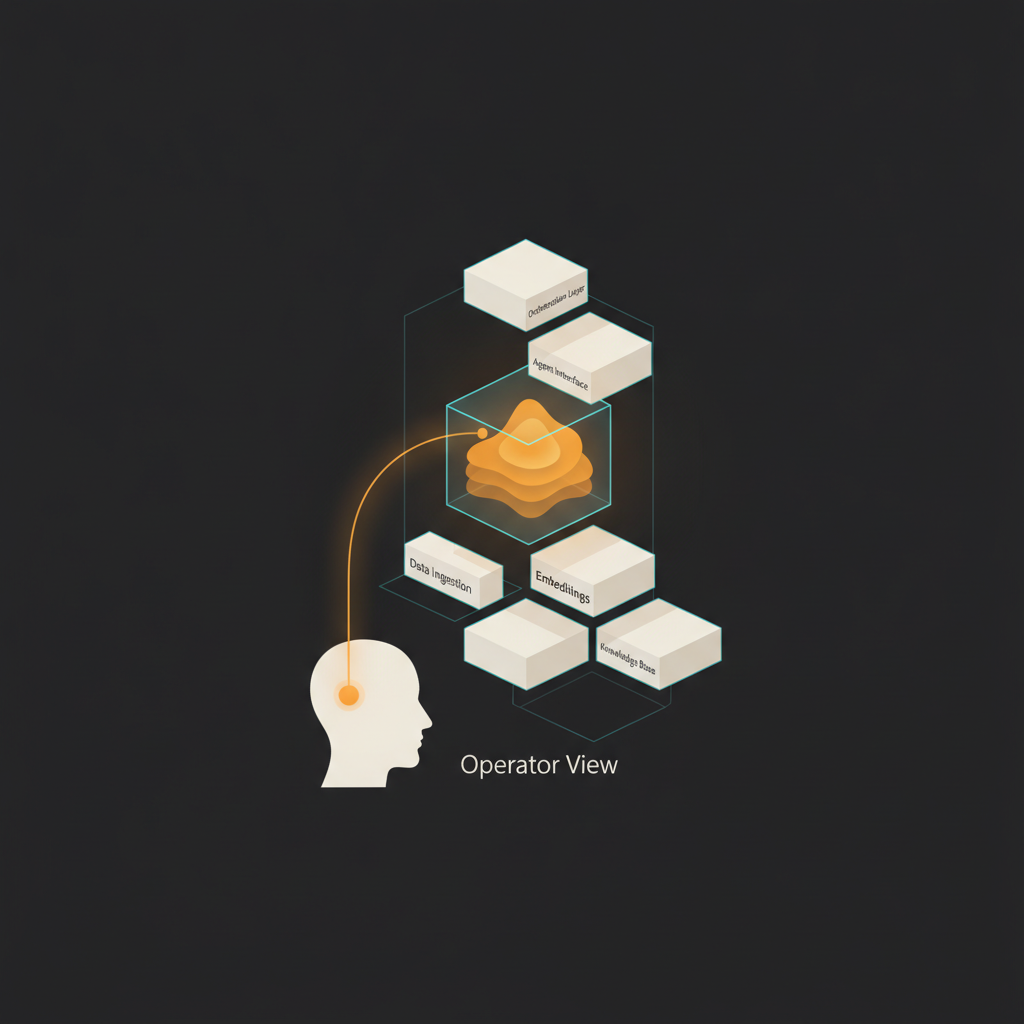
Embeddings are the numerical fingerprints your systems use to compare text. They power semantic search ("find me documents that mean the same thing, not just share keywords"), retrieval-augmented chat (the part of a chatbot that fetches the right policy before answering), deduplication, and classification. If the fingerprints are noisy in your language, every downstream system gets noisier too.
SkMTEB is the first serious yardstick for Slovak embeddings. Its authors evaluated 31 models across 31 datasets and seven task types. For an operator, that is the difference between guessing and procuring.
Operator view of where embeddings sit in a Slovak support stack
What SkMTEB actually measures
SkMTEB follows the structure of MTEB, the Massive Text Embedding Benchmark, which is the de facto standard for evaluating embedding models in English and a handful of other languages. The Slovak version contributes new datasets and adapts existing ones so that the seven task types map onto real business problems.
Here is how to read those task types as an operator:
Retrieval: how well the model finds the right document given a question. This is the core of any internal search or RAG (retrieval-augmented generation) chatbot.
Reranking: given a shortlist of candidate documents, how well the model orders them by relevance. Often a cheaper second pass on top of retrieval.
Semantic textual similarity (STS): how close two sentences are in meaning. Useful for deduplication and matching customer queries to known issues.
Classification: assigning labels (urgent, billing, product question). The backbone of automatic ticket routing.
Clustering: grouping similar texts without labels. Useful for discovering new themes in customer feedback.
Pair classification: deciding whether two texts share a relationship (paraphrase, contradiction, entailment).
Bitext mining: finding sentence pairs that translate each other across languages. Relevant if you maintain bilingual knowledge bases.
The headline claim is that SkMTEB offers nearly four times the depth of previous multilingual benchmark coverage for Slovak. In practice that means you can pick a model on the task that matches your use case, not on an average score that hides large weaknesses.
A simple framework for picking an embedding model
Before you pull benchmark numbers, decide what you are optimizing. Most operators want one of three things: better search quality, cheaper inference, or lower latency in a user-facing product. They trade against each other.
Use case
Primary task type
What to optimize
Acceptable monthly cost ceiling
Slovak RAG chatbot for support
Retrieval, Reranking
Top-10 retrieval accuracy
Mid (model serving plus vector DB)
Ticket routing into 20 queues
Classification
F1 on minority classes
Low (batch, no latency floor)
Knowledge base deduplication
STS, Clustering
Pairwise similarity quality
Low (one-off plus weekly job)
Cross-language product catalog
Bitext mining
Recall at high precision
Mid to high
Voice-of-customer themes
Clustering
Cluster purity
Low (monthly batch)
The point of the table is not the exact numbers, it is the discipline: pick one task type, pick one metric, set a budget, then read the benchmark.
How the SkMTEB paper structures the comparison
The authors evaluate 31 models, which is enough to cover the realistic shortlist any operator will consider: small multilingual models suitable for on-premise deployment, larger multilingual models from major labs, and models specifically adapted to Slovak through additional training.
The adaptation result is the one to pay attention to. Taking a strong multilingual base model and continuing training on Slovak data often closes the gap to much larger general-purpose models, at a fraction of the inference cost. For a buyer, that means a small fine-tuned model on your own hardware can be both cheaper and more accurate than a frontier API call.
Running your own SkMTEB-style eval in an afternoon
You do not need to reproduce the whole paper to make a decision. You need to evaluate two or three candidate models against the one or two task types that match your business. The Python ecosystem makes this short.
# Quick Slovak retrieval eval: compare two embedding models on your own data.# Run this against ~200 question/document pairs from your knowledge base.from sentence_transformers import SentenceTransformer, utilimport pandas as pdpairs = pd.read_csv("sk_eval_pairs.csv") # columns: question, correct_doc_iddocs = pd.read_csv("sk_kb.csv") # columns: doc_id, textcandidates = { "multilingual-base": "intfloat/multilingual-e5-base", "multilingual-large": "intfloat/multilingual-e5-large",}for name, model_id in candidates.items(): model = SentenceTransformer(model_id) doc_vecs = model.encode(docs["text"].tolist(), normalize_embeddings=True)
That script answers one question: out of every Slovak support query, how often does the right article appear in the top five results? A move from 0.62 to 0.81 is the difference between a useful assistant and one that frustrates customers.
You can set up the evaluation environment with this:
# Minimal environment for a Slovak embedding eval.python -m venv.venv && source.venv/bin/activatepip install sentence-transformers pandas mteb# Optional: pull SkMTEB tasks once they are released through mteb.python -c "import mteb; print([t for t in mteb.MTEB_REGISTRY if 'sk' in t.lower()])"
If you have a data engineer, they can wire this into your weekly evaluation job. If you do not, this script is short enough that a contractor can run it for you in a day.
Where embeddings sit in an agentic Slovak business
The reason to take this seriously now is that embeddings are the foundation under most agent stacks. An agent is only as good as its memory and its tools, and both of those run on embeddings.
flowchart LR A[Slovak customer query] --> B[Embedding model] B --> C[Vector search over KB] C --> D[Top-k documents] D --> E[LLM answers in Slovak] E --> F[Agent action: refund, escalate, reply] G[Eval set: SkMTEB-style] --> B G --> C H[Weekly regression check] --> G
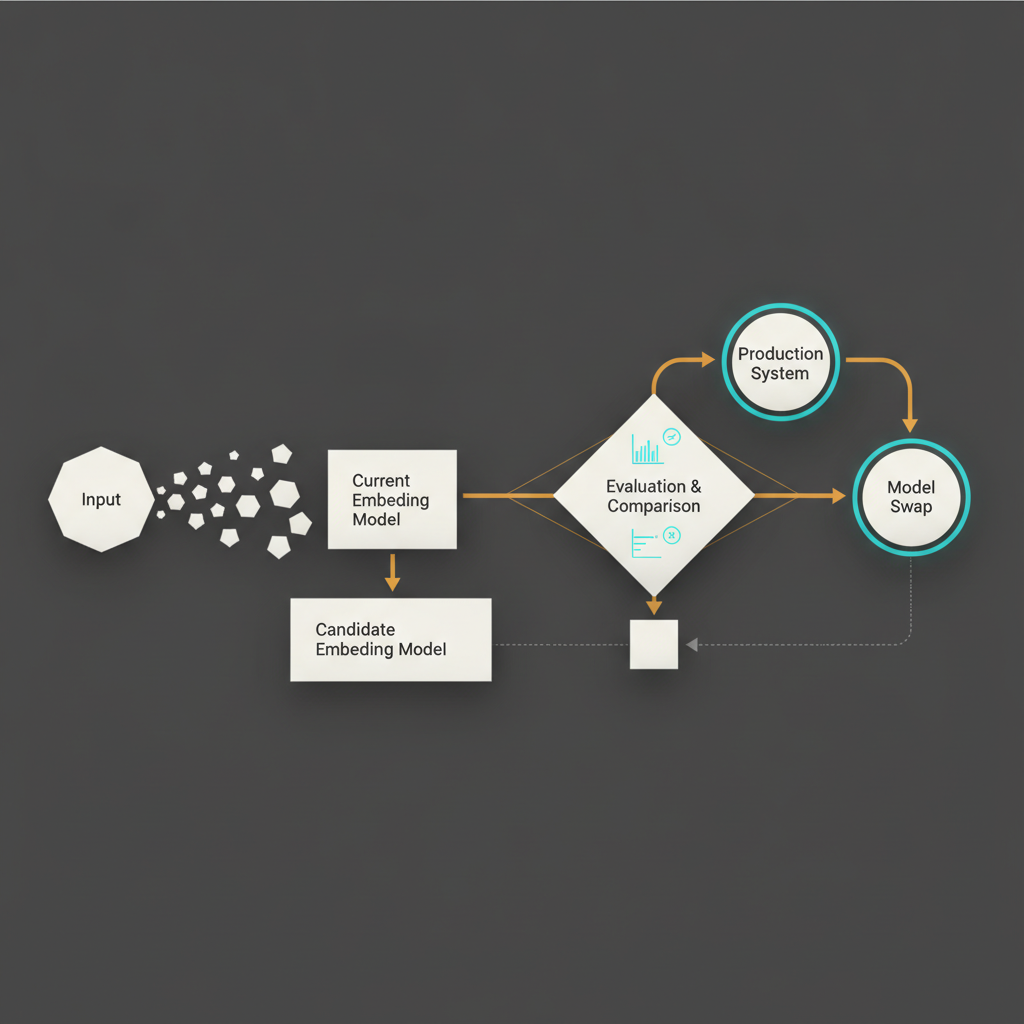
The diagram is the operator's mental model. The embedding model and the vector search step are where Slovak-specific quality lives. If you change the embedding model without an eval, you have changed the behavior of every downstream agent without measuring it. The right discipline is: every model swap goes through the eval set before it touches production.
This is the core idea of eval-driven operations: you do not promote a change unless the eval says so, and you do not trust vendor benchmarks for your language.
Eval-driven workflow for swapping embedding models in production
Adaptation: when to fine-tune instead of waiting
The SkMTEB paper makes a practical point: a multilingual base model adapted to Slovak often performs competitively with much larger general-purpose models. For an operator, this changes the build-versus-buy math.
The trade-offs in plain terms:
Use a frontier API embedding model. Lowest engineering effort. Highest per-call cost. Quality on Slovak is decent but not always best in class. You depend on a vendor's roadmap.
Use an off-the-shelf multilingual open model. No per-call cost beyond hosting. Quality varies; SkMTEB tells you which one to pick. Predictable.
Adapt an open model on Slovak data. Two to four weeks of work for a competent NLP engineer. Lowest long-term inference cost. Best fit for domain-specific vocabulary (legal, medical, banking). You own the model.
Option three has a hidden benefit that does not show up in cost spreadsheets: when your agent stack uses an embedding model you control, you can re-run the SkMTEB-style eval on every checkpoint and catch regressions before they reach customers. That governance discipline is what separates AI-native operations from AI-curious ones.
A rough cost sketch for adaptation
These numbers are illustrative, not from the paper. Use them to estimate.
Path
Setup time
Recurring cost (1M calls/mo)
Quality on Slovak
Control
Frontier API
1 day
High (per-call)
Good
Low
Off-the-shelf open model on GPU
1 week
Low (hosting only)
Variable, often good
Medium
Adapted open model
2-4 weeks plus data prep
Low (hosting only)
Best on your domain
High
The decision is rarely about peak quality. It is about whether you want to own the model that sits at the foundation of your agent stack.
What to do this quarter
Three concrete steps for an operator:
Inventory every place embeddings touch Slovak text. Search, chatbots, ticket routing, knowledge base, analytics. Most teams underestimate this by half.
Build a 200-pair eval set from real customer data. Questions on the left, correct document IDs on the right. This is the single highest-leverage artifact you will build this year.
Run two candidate models against it. Use the Python script above or a similar harness. Decide based on numbers, not vendor slides.
If the gap between candidates is large, you have your answer. If it is small, fall back on cost, latency, and the question of whether you want to own or rent the model.