SpatialClaw: Better Action Interfaces for Spatial Reasoning…
SpatialClaw argues spatial reasoning failures in VLMs stem from poor tool interfaces, not weak models. Tighter schemas and structured outputs cut errors…
June 12, 2026·8 min read
Frequently asked questions
Do we need to wait for better vision-language models to deploy spatial agents?
No. The research suggests current models are capable enough if the action interface is tight. Most failed pilots fail on integration discipline, not model capability. You can start now, against a constrained set of questions, and widen the scope as your evals hold.
How is this different from just using function calling with our existing model?
Function calling is the mechanism. The action interface is the design. Many teams enable function calling, list a dozen tools with prose descriptions, and call it done. Tight typing, structured outputs, narrow tool boundaries, and tool-call evals are what separate a working system from a demo.
What is the smallest useful first project?
Pick one spatial question that costs you money today: misrouted pallets, missed shelf gaps, blocked exits on camera. Label 300 examples. Wire up two or three perception tools behind a typed interface. Run the eval nightly. You will know within two weeks if the approach holds.
The only platform to run an AI-native company.
14-day trial. No DevOps. No Sales call. Provisioned in under a minute.
No. You need an engineering lead who treats the tool interface as a product surface, and an operator who owns the eval set. The perception tools can be off the shelf. The model can be a hosted vision-language model. The work is in the contract between them, and that work is mostly schema design and evaluation, not research.
How do we handle the cases the agent gets wrong?
Two paths. First, route low-confidence answers to a human reviewer and feed those reviews back into the eval set. Second, when you see a repeated failure pattern, add a tool or tighten a schema rather than retraining the model. Most spatial failures are interface problems, not knowledge problems.
Spatial reasoning failures cost real money in warehouses, robotics, and inspection work where agents must judge where things are in 3D.
SpatialClaw research argues the bottleneck is not better models but a better action interface between the vision-language model and its perception tools.
For operators, this means cheaper deployments: fewer custom models, more reuse of existing perception modules behind a stable agent contract.
Treat the agent's tool interface as a product surface. Version it, evaluate it, and measure tool-call accuracy alongside task success.
Vision-language models, the systems that read an image and answer questions about it, are competent at naming what they see but weak at reasoning about where things sit in 3D space. That gap matters for any operator running cameras in a warehouse, a clinic, a factory floor, or a retail aisle. New work on SpatialClaw (see the arXiv preprint) argues that the fix is not a bigger model; it is a better action interface between the agent and the perception tools it already has.
A diagram of a vision-language agent calling spatial perception tools
Why spatial reasoning is the expensive failure mode
Most agent demos run on flat tasks: read a document, draft a reply, look up a record. The work gets harder the moment the agent has to act on the physical world. A pick-and-place robot has to know which box is in front of which. An inspection agent has to know whether a crack is on the near surface or behind it. A retail audit agent has to know whether the third shelf from the top is empty.
When the agent gets this wrong, the cost is not a typo. It is a wrong pick, a missed defect, a re-shoot. Those errors compound across thousands of decisions a day, and they are the reason many computer vision projects stall after the pilot.
The instinct is to throw a bigger vision-language model at the problem. That is expensive and slow. Frontier models cost more per call, take longer to respond, and still miss on depth, occlusion, and relative position. The SpatialClaw work suggests a cheaper path: keep the specialist perception modules you already have (depth estimators, segmenters, pose estimators), and fix the way the agent talks to them.
The action interface, in plain terms
An action interface is the menu of tools the agent can call and the format it must use to call them. In a typical setup, a vision-language model is given a list of perception tools and asked to choose one, fill in the arguments, and interpret the result. This sounds simple. In practice, the agent fails in three repeatable ways:
It picks the wrong tool because two tools sound similar in their description.
It fills in the right tool with the wrong arguments because the schema is loose.
It misreads the tool's output because the output format is ambiguous.
The fix is not cleverness in the model. It is discipline in the interface. Tight tool names, narrow argument types, and structured outputs reduce the surface area where the agent can go wrong.
What the research changes
SpatialClaw reframes the problem as interface design, not model design. The agent does not need to learn 3D geometry from scratch; it needs to learn to dispatch to the right specialist and combine results. That is a much smaller learning problem, and one that transfers across domains.
For an operator, this distinction is the difference between hiring a perception research team and configuring an off-the-shelf agent against tools you have already paid for.
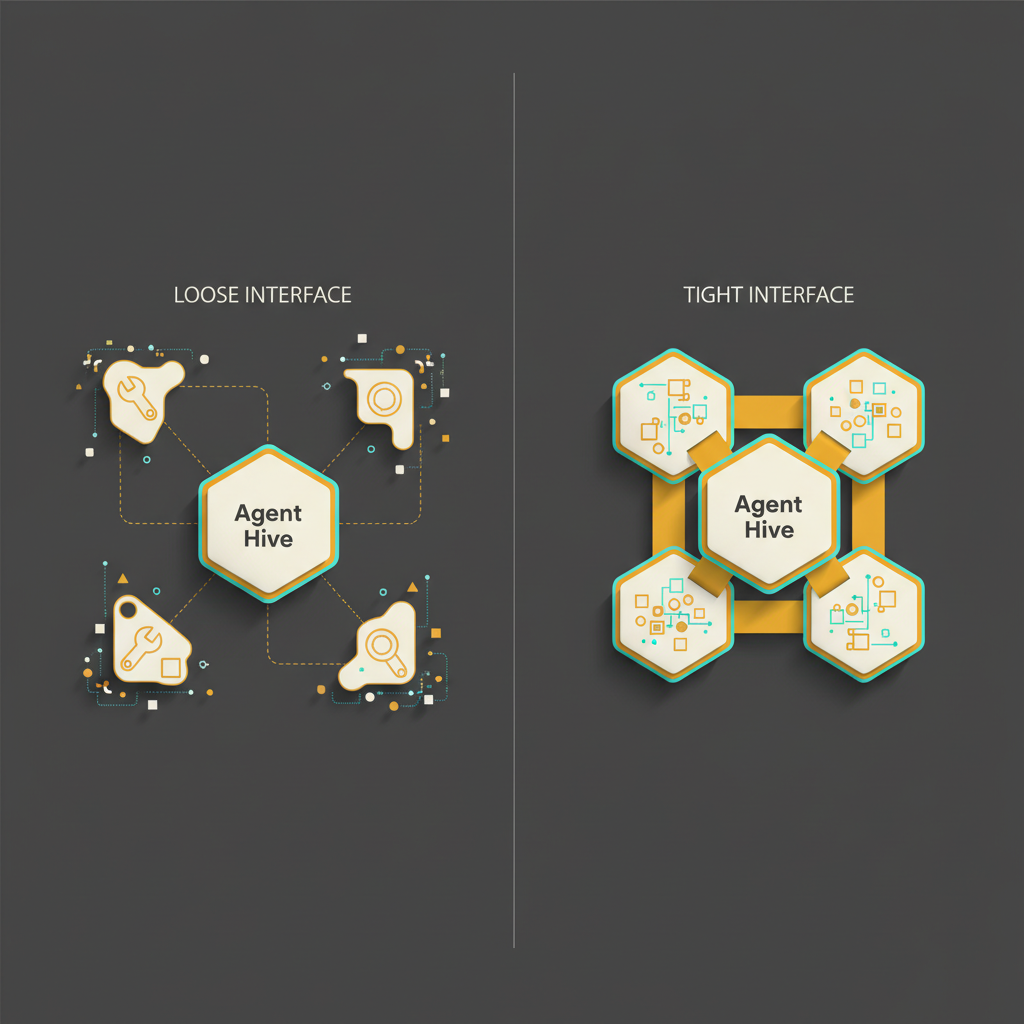
A side-by-side: three ways to build a spatial agent
The table below compares three common architectures for an agent that has to answer spatial questions about a scene, for example: "Is the forklift blocking aisle 4?"
Approach
What you build
Cost per query
Reuse of existing perception
Failure mode
Single large VLM
One frontier model, prompted
High
None
Confident but wrong on depth and occlusion
Tool-augmented VLM, loose interface
VLM plus a bag of perception APIs
Medium
High
Wrong tool, wrong args, brittle
Tool-augmented VLM, tight action interface
Same tools, strict schema, typed outputs
Medium
High
Fails loudly, easier to debug
The third row is what SpatialClaw is pointing at. The tools do not change. The interface between the agent and the tools does.
A comparison of loose versus tight tool interfaces for an agent
What a tight action interface looks like
A loose tool definition reads like a sentence. A tight one reads like a contract. Here is the kind of schema an operator would hand to an agent for a depth-aware perception tool. The point is that every field is typed, every output is structured, and the agent cannot return free-form prose where a number is expected.
{ "name": "estimate_relative_depth", "description": "Given an image and two bounding boxes, return which box is closer to the camera.", "parameters": { "type": "object", "properties": { "image_id": { "type": "string" }, "box_a": { "type": "array", "items": { "type": "number" }, "minItems": 4, "maxItems": 4 }, "box_b": { "type": "array", "items": { "type": "number" }, "minItems"
That schema gives the agent no room to invent a third option. Either it returns "a", "b", or "equal", with a confidence number. Downstream code can branch on those three values without parsing English.
Wiring it into an agent loop
The agent loop below is a minimal sketch of how an operator would call a sequence of perception tools and combine the results to answer a spatial question. The point of the snippet is to show that the orchestration logic is small and readable when the tools have tight schemas.
# Answer: "Is the forklift blocking aisle 4?"# Each tool returns a typed dict; the agent does not parse free text.scene = detect_objects(image_id="cam7_2024_01_15_0930")forklift = find(scene, label="forklift")aisle = find(scene, label="aisle_marker", attribute="4")if forklift is None or aisle is None: return {"blocking": False, "reason": "missing_evidence"}overlap = box_overlap_2d(forklift.box, aisle.box)depth = estimate_relative_depth( image_id="cam7_2024_01_15_0930",
The vision-language model is still in the loop, choosing which tools to call and in what order. But the glue is small, auditable, and testable. That last word is the one that matters for governance.
The agent, the tools, and the contract between them
Here is the same idea as a diagram. The agent sits in the middle. The perception tools sit on the right. The contract between them, the action interface, is the thing the operator owns and versions.
flowchart LR U[Operator question] --> A[VLM agent] A -->|tool call, typed args| C[Action interface contract] C --> T1[Object detector] C --> T2[Depth estimator] C --> T3[Pose estimator] T1 -->|typed result| C T2 -->|typed result| C T3 -->|typed result| C C --> A A --> R[Structured answer + confidence]
This picture is worth internalising before you sign any vendor contract for an agent product. If the vendor cannot show you the action interface and let you version it, you are buying a black box. If they can, you are buying a system you can evaluate.
Running evals on the interface, not just the model
Eval-driven operations means measuring the agent the way you measure a sales rep: with a scorecard, run regularly, against fresh cases. For spatial agents, the scorecard needs two layers.
Task-level evals: did the agent answer the operator's question correctly? For "is the forklift blocking aisle 4?", the answer is yes or no, and you can grade it against ground truth from your cameras.
Tool-call evals: did the agent call the right tools, in the right order, with the right arguments? This catches the cases where the agent gets the right answer by luck.
You want both. Task-level evals tell you if the system works today. Tool-call evals tell you if it will keep working when you swap a tool or update the model.
A practical cadence:
Build a fixed set of 200 to 500 labeled spatial queries from your own footage.
Run the agent against the set nightly.
Track three numbers: task accuracy, tool-call accuracy, and average tools called per query.
Alert on regressions of more than 2 percent on any of the three.
That YAML file is small enough to fit in a pull request and clear enough that a non-technical operator can read it. That is the level of legibility you want from your agent stack.
What this means for your build-or-buy decision
If you are evaluating an agent product or an internal build for spatial work, three questions cut through the demo:
Can you see the action interface? If the tool schemas are hidden, your governance team cannot audit the system, and your engineers cannot fix it when it drifts.
Are tool calls logged and replayable? You should be able to take any past query, re-run it offline against a new model, and compare results. That is how you upgrade without praying.
Is there a tool-call eval, not just an accuracy number? A vendor that only quotes end-to-end accuracy is hiding the brittle middle.
The SpatialClaw line of work does not give you a product to buy. It gives you a vocabulary to use when you are buying or building one. The headline is small and useful: in spatial agents, the interface is the system. Models will change every six months. The interface is what you actually own.